Foundations of Data Engineering and Its Role in AI Projects.
May 20, 2022
When was the last time you tried to speak to an AI assistant like Google Assistant or Alexa, trying to check the latest news or request a song? Or have you tried applying for a loan on a fintech app and you need to wait a few minutes before your loan is approved?
If your answer to any of these questions is yes, then you have interacted with examples of Artificial intelligence that have been deployed in a cloud environment. Data engineering is one of the technical areas in AI deployment that plays a huge role in ensuring that such applications work seamlessly.
What does data engineering involve, and how does it contribute to the deployment or development of AI models? Well, in this article we will briefly answer those two questions.
Data Engineering
Data engineering refers to the practice of designing and building systems for collecting, storing, and analyzing data at a scale. Data engineers provide companies with data by taking it from source systems via data pipelines using ETL or ELT processes and then transferring it to the target platform, e.g. a Data Warehouse, Data Lake, or Data Lakehouse.
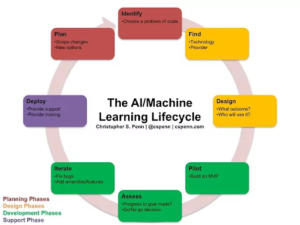
Looking at the general artificial intelligence software development life cycle, data engineering mainly comes in at the deploy stage, as per step 7 in the diagram below.
Data Pipeline
A data pipeline is a series of data processing steps. If the data is not currently loaded into the data platform, then it is ingested at the beginning of the pipeline. Then there are a series of steps in which each step delivers an output that is the input to the next step. This continues until the pipeline is complete. In some cases, independent steps may be run in parallel.
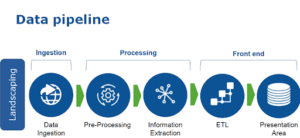
Data pipelines consist of three key elements: a source, a processing step or steps, and a destination. In some data pipelines, the destination may be called a sink. Data pipelines enable the flow of data from an application to a data warehouse, from a data lake to an analytics database, or into a payment processing system, for example. Data pipelines also may have the same source and sink, such that the pipeline is purely about modifying the data set. Any time data is processed between point A and point B (or points B, C, and D), there is a data pipeline between those points.
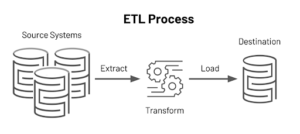
ETL (Extract, Transform, Load)
ETL, which stands for extract, transform and load, is a data integration process that combines data from multiple data sources into a single, consistent data store that is loaded into a data warehouse or other target system.
Data Warehouse
A data warehouse is a large collection of business data used to help an organization make decisions. The concept of the data warehouse has existed since the 1980s, when it was developed to help transition data from merely powering operations to fueling decision support systems that reveal business intelligence. The large amount of data in data warehouses comes from different places such as internal applications such as marketing, sales, and finance; customer-facing apps; and external partner systems, among others.
Some of the common frameworks and tools used in data engineering include:
- Amazon Redshift a fully managed cloud data warehouse by Amazon, read more on RedShift here
- BigQuery a fully managed cloud data warehouse built by google, read more on Big Query here
- Tableau and Power BI business intelligence tools for building dashboards, read more here on Power BI and here for Tableau.
- Apache Hive.
- Snowflake.
- Airflow.
- Apache Kafka.
Data engineering ensures that large volumes of data used in building artificial intelligence projects is readily available, by building ETL and ELT pipelines to load and process data.
In the next article, we are going to cover the roles of data engineers and in future we will learn how to build data pipelines that scale using python. Happy coding.